An Introductory Guide to Disaster Recovery on AWS
Developing an effective disaster recovery plan is an integral part of every organization’s cloud journey. Cloud-based disaster recovery on Amazon Web Services allows customers to protect both on-premises services and cloud workloads from data corruption, downtime, natural disasters, and more. Today, we’ll explore the need-to-know basics of disaster recovery and why our team of experts recommends AWS Elastic Disaster Recovery.
The Basics –A Whole Lot of Words That Start with “R”
1. Reliability is the ability of a workload to perform its intended function correctly and consistently when it’s expected to.
2. Resiliency is the capability to recover when stressed by load (more requests for service), attacks (either accidental through a bug, or deliberate through intention), and failure of any component in the workload’s components.
3. High availability is a measure of operational performance– can your system operate without failure in a predetermined timeframe? High availability is prioritized in the initial design and architecture of an environment and contributes to an organization’s business continuity.
4. Redundancy is the replication of workloads into multiple availability zones and regions. More replications dispersed across availability zones and regions provide customers with increased resiliency.
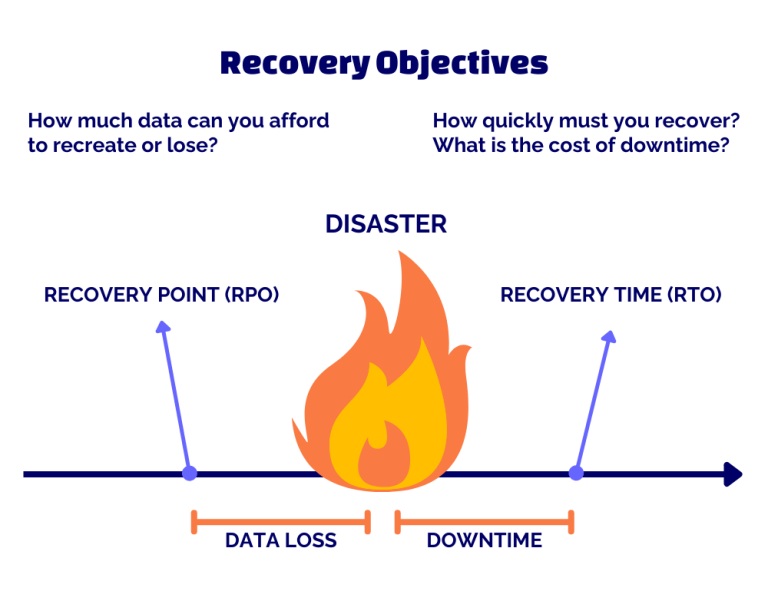
5. Recovery Point Objective (RPO): In any disaster recovery scenario, some amount of data loss should be expected. The Recovery Point Objective is a time-based measurement of the maximum amount of data loss that an organization can tolerate.
6. The Recovery Time Objective (RTO) is the longest amount of time that an organization can tolerate between a disaster event and the continuation of services.
Four Disaster Recovery Strategies on AWS
AWS recommends four main disaster recovery strategies. Each varies in complexity, speed, and cost.
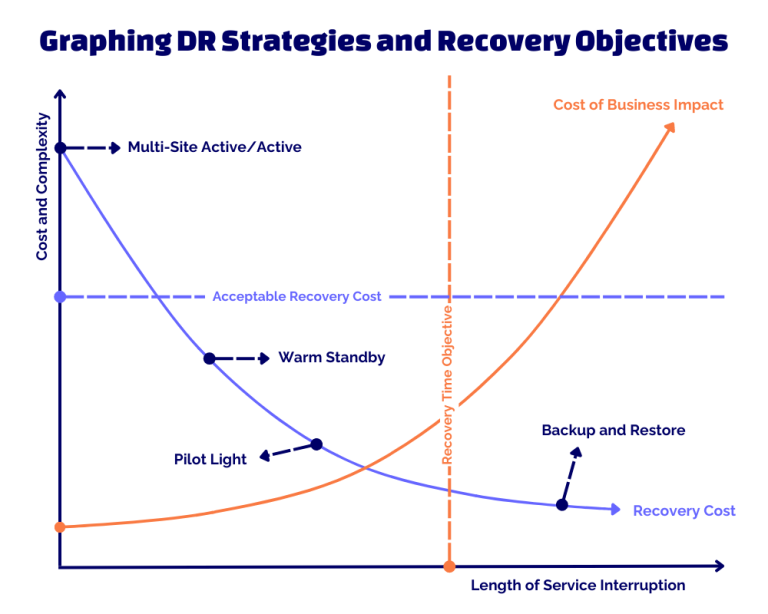
1. Backup and restore is the simplest and most affordable strategy that mitigates against data loss and corruption. Depending on the configuration, it can also protect against regional disasters. The process is just as the name describes: data and systems are backed up into the cloud. If necessary, the backup is used to restore workloads. Infrastructure-as-code is used to simplify the restoration process and minimize recovery times.
2. A pilot light strategy dictates that customers replicate data from one region to another, provisioning a copy that can be turned on in the event of a data disaster. Data replication and backup resources like databases or object storage are always on. Application servers are loaded but switched off; they are turned on to perform testing and failovers. By minimizing active resources but creating the configuration and capabilities to deploy it in place, organizations can keep disaster recovery costs low and simplify the recovery process.
3. A warm standby approach creates a scaled down, but fully functional copy of your production environment in another region. This strategy is very similar to the pilot light approach, but there is one key difference; while a pilot light strategy requires “turning on” servers and scaling up, warm standby only requires scaling up because everything is already deployed and running. This method decreases recovery times and makes it easier to perform testing. Additionally, customers can implement continuous testing if desired.
4. A multi-site active/active approach provides the highest availability, with near-zero recovery objectives, and is the most expensive option. In this scenario, customers run workloads simultaneously in multiple regions. Because workloads are constantly running in multiple regions, failovers are not a factor in this approach. Testing this scenario is focused on seeing how a deployment reacts when one region is down. Backup and recovery are still required with this strategy to allow for protection against data corruption.
Why Choose Cloud-Based Disaster Recovery?
There aren’t significant barriers to entry for getting started with cloud-based disaster recovery. Unlike traditional DR, cloud-based DR does not require any large upfront investments in hardware when organizations get started or as needs grow. Scaling on the cloud is easy, allowing customers to quickly add or remove replicating servers when an environment changes. Additionally, in most of the DR strategies we ran through above, customers only pay for their full DR site when it is needed for testing or recovery. Finally, when testing is necessary, it does not disrupt regular business operations.
When customers choose cloud-based DR on AWS, they reap some of AWS’ other key benefits, including its shared responsibility model. Under this model, AWS is responsible for ongoing management and infrastructure overhead, lowering customers’ IT management overhead.
Common Disaster Recovery Pain Points
Our team has spent years developing our resiliency and disaster recovery practice. In that time, we’ve seen the same issues come up over and over as customers transition to a cloud-based DR strategy.
1. High duplicate costs: Customers currently using traditional on-premises disaster recovery solutions often pay high duplicate costs for the compute, storage, network, and software licenses necessary to run a DR site.
2. Diverse infrastructure and OS types: Most organizations rely on different infrastructure and operating system types or versions. Finding a DR solution that is compatible with everything a customer uses can be difficult.
3. Server compatibility: When customers are replicating servers from different infrastructure, server conversions must be completed to ensure workloads can run on AWS. If a conversion isn’t successful, servers will not boot up properly in the DR region.
4. Not meeting objectives: Many customers experience unreliable results or are incapable of reaching their required RPO or RTO during testing.
5. Busy workloads: Busy workloads like SQL Servers or SAP workloads must be continuously updated. If these workloads are too busy to update and a customer may not be able to achieve point-in-time recovery and data loss may occur.
6. Inadequate testing: Solutions that must disrupt normal operations for testing often inhibit customers from routine tests. Frequent testing is essential for optimal recovery– without it organizations risk a failed recovery during a disaster.
7. Different tools per application: Depending on the application, customers using traditional disaster recovery solutions may require highly specialized, expensive replication software in order to recover. This is often a barrier to entry for DR solutions.
8. Scaling on-premises workloads requires costly up-front investments and diligent planning so organizations can order the correct physical infrastructure.
Our Preferred Solution: AWS Elastic Disaster Recovery
What is AWS Elastic Disaster Recovery?
AWS Elastic Disaster Recovery is AWS’ native DR solution that evolved from AWS CloudEndure. AWS DRS minimizes downtime and data loss with fast, reliable recovery of on-premises and cloud-based applications using affordable storage, minimal compute, and point-in-time recovery.
How It Works
1. Set up– First install the AWS DRS Agent and define settings for launch and replication. Once complete, continuous data replication begins.
2. Testing– Immediately after set up is complete, testing is necessary to ensure all intended workloads will recover.
3. Maintenance– After initial set up and testing, routine maintenance is required for optimal recovery. This includes monitoring data replication and performing regular recovery and failback drills.
Should your organization deal with a disaster, recovery can be launched in minutes. Customers can choose between using the most up-to-date recovery instances or failing over to a previous point in time, which is necessary for data corruption. After launching, recovery instances will continue running on AWS until all issues with the customer’s primary site are resolved. Then, customers will failback to their primary site and all instances on AWS should be turned off to avoid unnecessary costs.
Standout Features
1. Continuous block-level replication enables recovery within minutes of an outage. It replicates servers, including the operating system, system state configuration, databases, applications, and files. AWS DRS continuously copies any changes, ensuring that data replication is always up-to-date.
2. AWS DRS allows for point-in-time recovery, a key defense against ransomware and data corruption.
3. Non-disruptive testing allows customers to continue using applications during replication, so testing doesn’t have to happen at odd hours. Testing is a crucial part of ensuring full recovery.
4. AWS DRS is affordable– it replicates applications and data to a staging area subnet and only spins servers up on AWS with fully provisioned compute and storage during failover or drills.
Why AWS DRS?
Our team prefers AWS DRS for three key reasons: its flexibility, reliability, and automation capabilities.
1. Flexibility
AWS DRS supports a wide range of platforms, allowing customers to replicate data from any source. This range of service opens the door to DR for most customers. Supported environments include common databases like Oracle and Microsoft SQL Servers and SAP mission-critical applications. AWS DRS supports most common Windows and Linux operating systems. If required, customers can failback to on-premises or cloud environments.
2. Reliability
AWS DRS provides continuous block-level replication of workloads, including all of the data in source servers, without performance impact. Since data is constantly replicated and ready to be launched, customers can achieve RPOs of seconds. AWS DRS automates server conversion and orchestration, enabling RTOs of minutes. Point-in-time recovery protects users from IT disruptions caused by ransomware, data corruption, accidental user error, or bad patches.
3. Highly automated
AWS DRS is simple to use– you don’t need an in-house subject matter expert to operate it. There is a unified process for testing, recovering, and failing back. Testing is easy and non-disruptive. To further simplify testing and recovery, our team created a scripted process for automating blueprint changes. This process allows for simple, at-scale changes of blueprints so organizations can quickly change configurations between production DR and test configurations and remediate issues.
Conclusion
Disaster recovery plans are a worthy investment for every organization. That being said, your organization should find a great solution, not just a good one. AWS DRS is a good fit for those searching for an affordable introduction to cloud-based disaster recovery. It may not work for every use case, but it’s a great option for most. We’re always happy to help organizations assess their options.
While AWS DRS is easy to use on its own, it’s even easier for organizations to get started when they partner with experts like us. Our team works with organizations for one-time disaster recovery set ups and longer Disaster-Recovery-as-a-Service engagements. Connect with our team to explore your options.